arXiv
arXiv
 Code
Code


The main goal is to propose a framework to critically evaluate existing model fingerprinting schemes under a more realistic scenario where the model host is maliciously attacking the verification process while preserving the model utility.
Thus far, lack of such systematic evaluation has led to (i) fingerprinting schemes being introduced without proper robustness guardrails, (ii) most of those methods failing under easy-to-apply attack scenarios, and (iii) comparisons to existing baselines being inconsistent. To rectify this status quo, our goal is (i) to provide user-friendly benchmarks that can easily measure the utility-ASR curve for any fingerprinting methods of the user's choice under several attacks (see our GitHub repo), (ii) to provide a family of attacks that are powerful against existing family of fingerprints, and (iii) to demonstrate that such systematic stress-test on fingerprints is necessary by numerically showcasing how existing methods fail under our attacks.
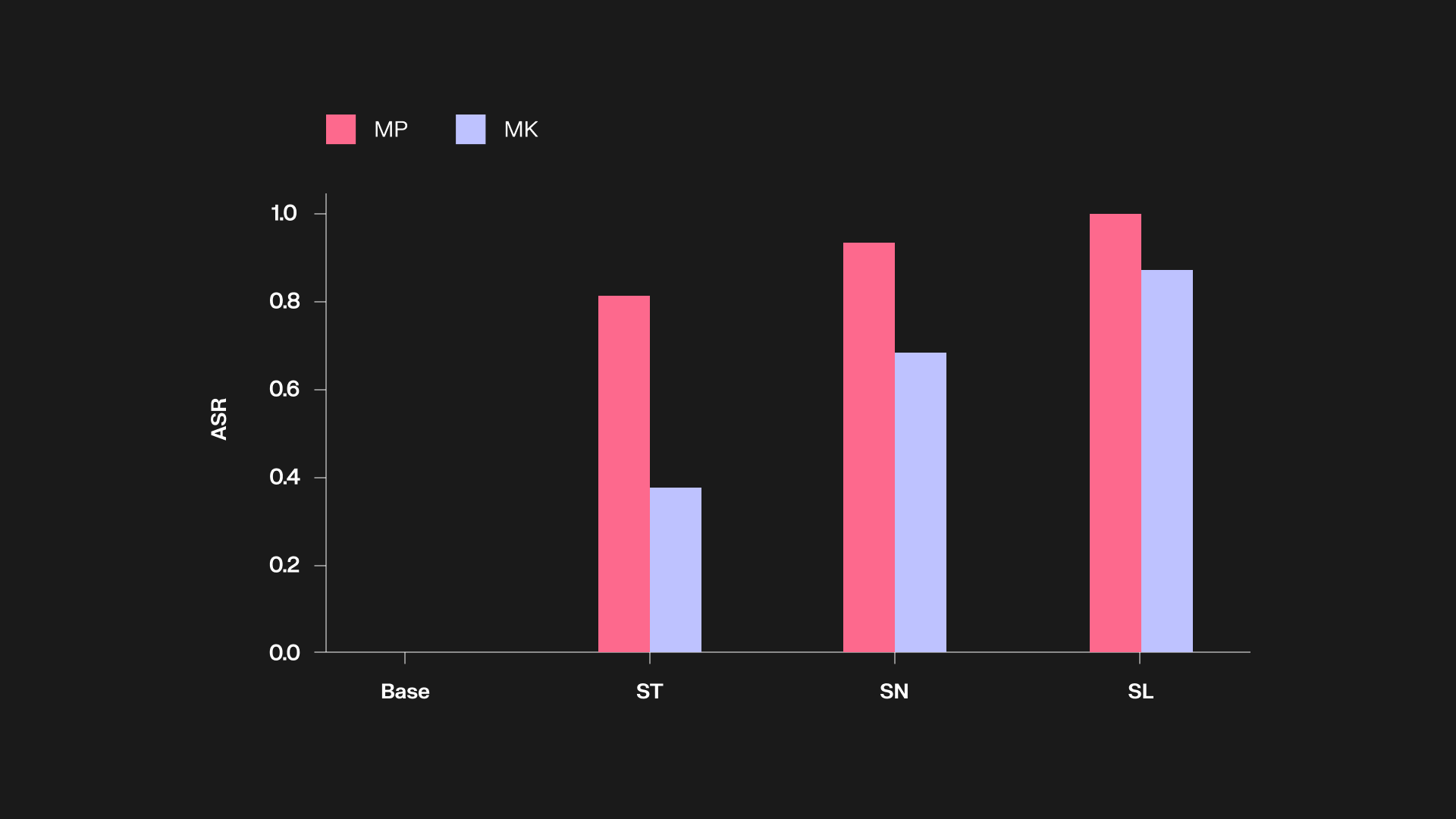
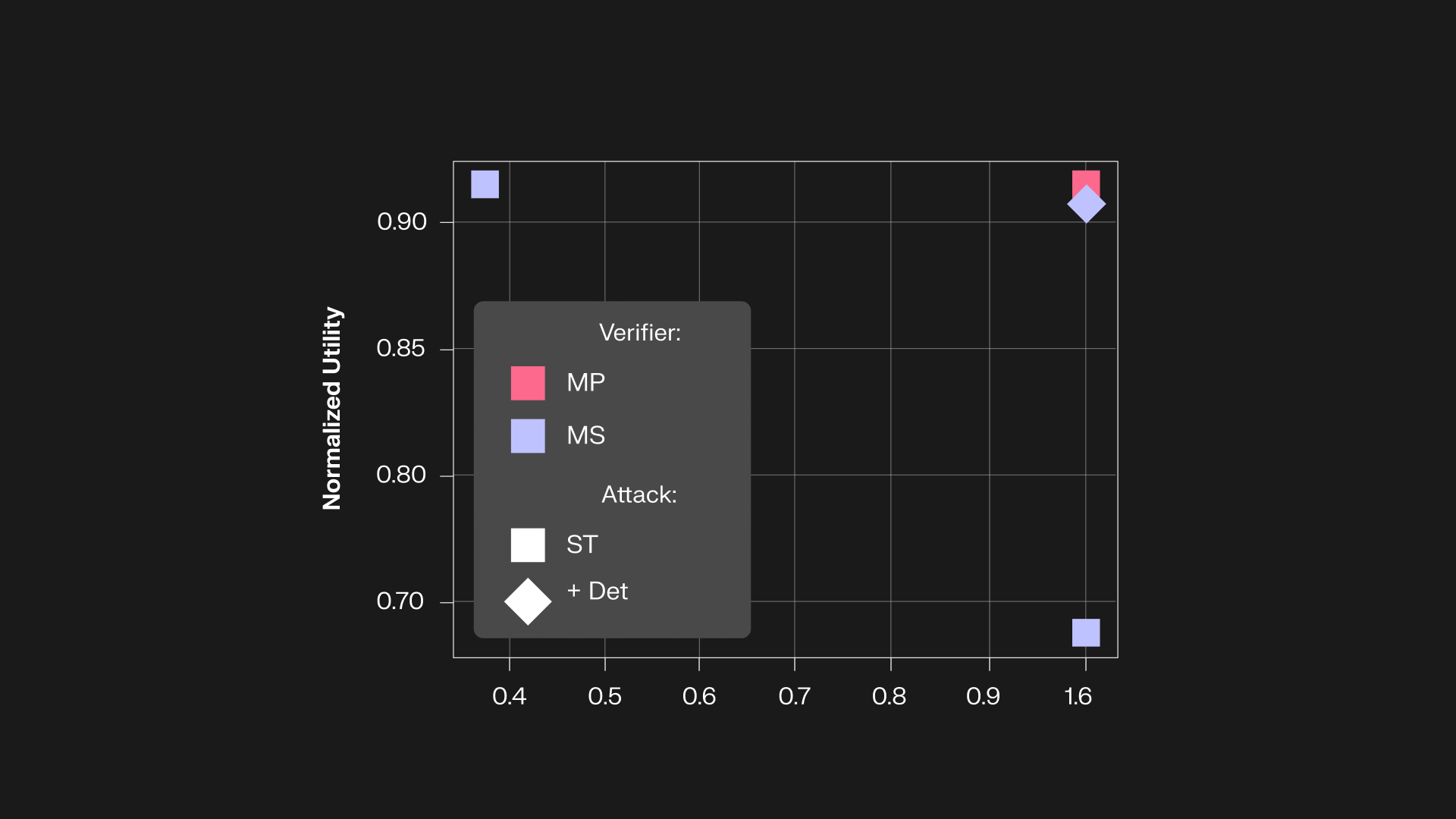
In our repo we provide implementations of Instructional FP, Chain&Hash, Perinucleus FP, Implicit FP, FPEdit, EditMF, RoFL, MergePrint, ProFLingo, and DSWatermark and test their robustness to the four types of vulnerabilities under our corresponding attacks.
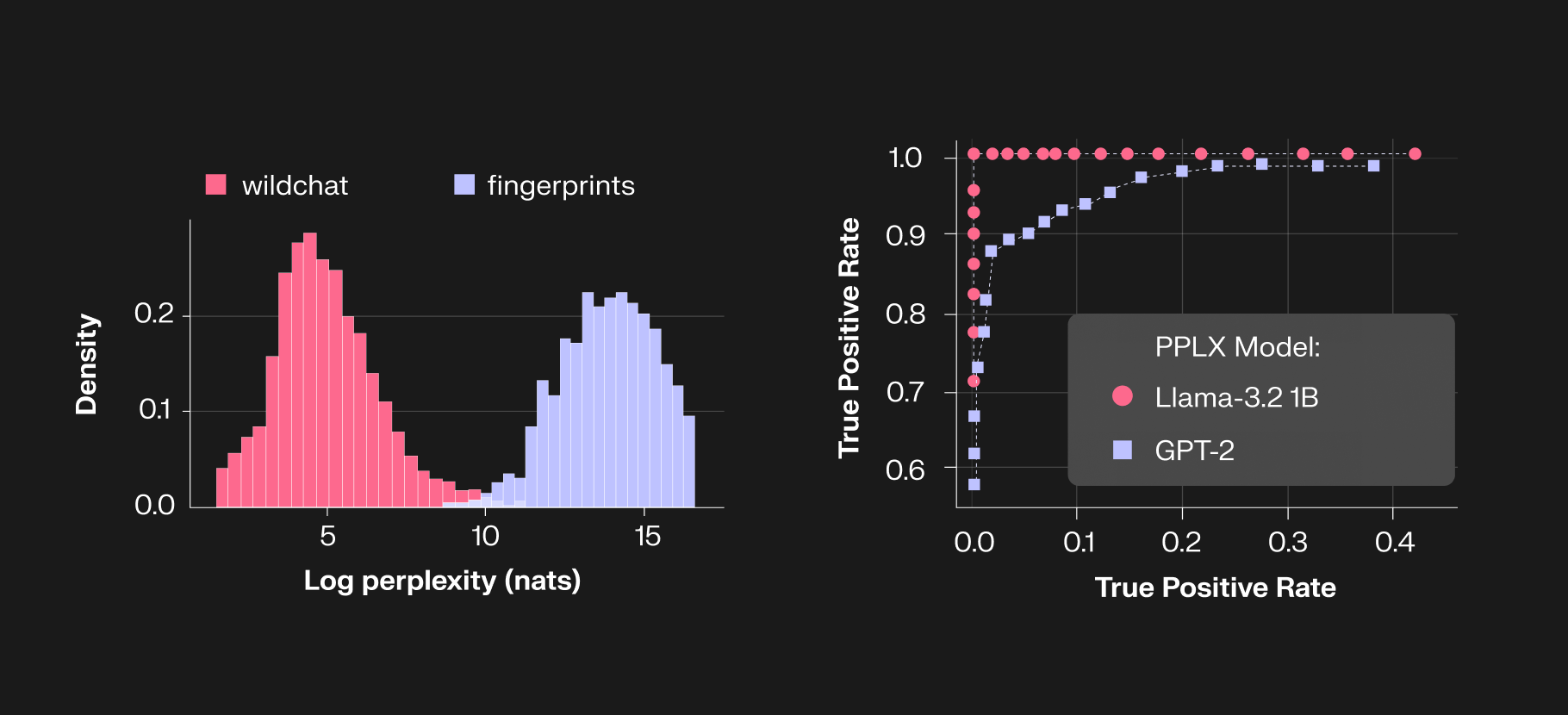
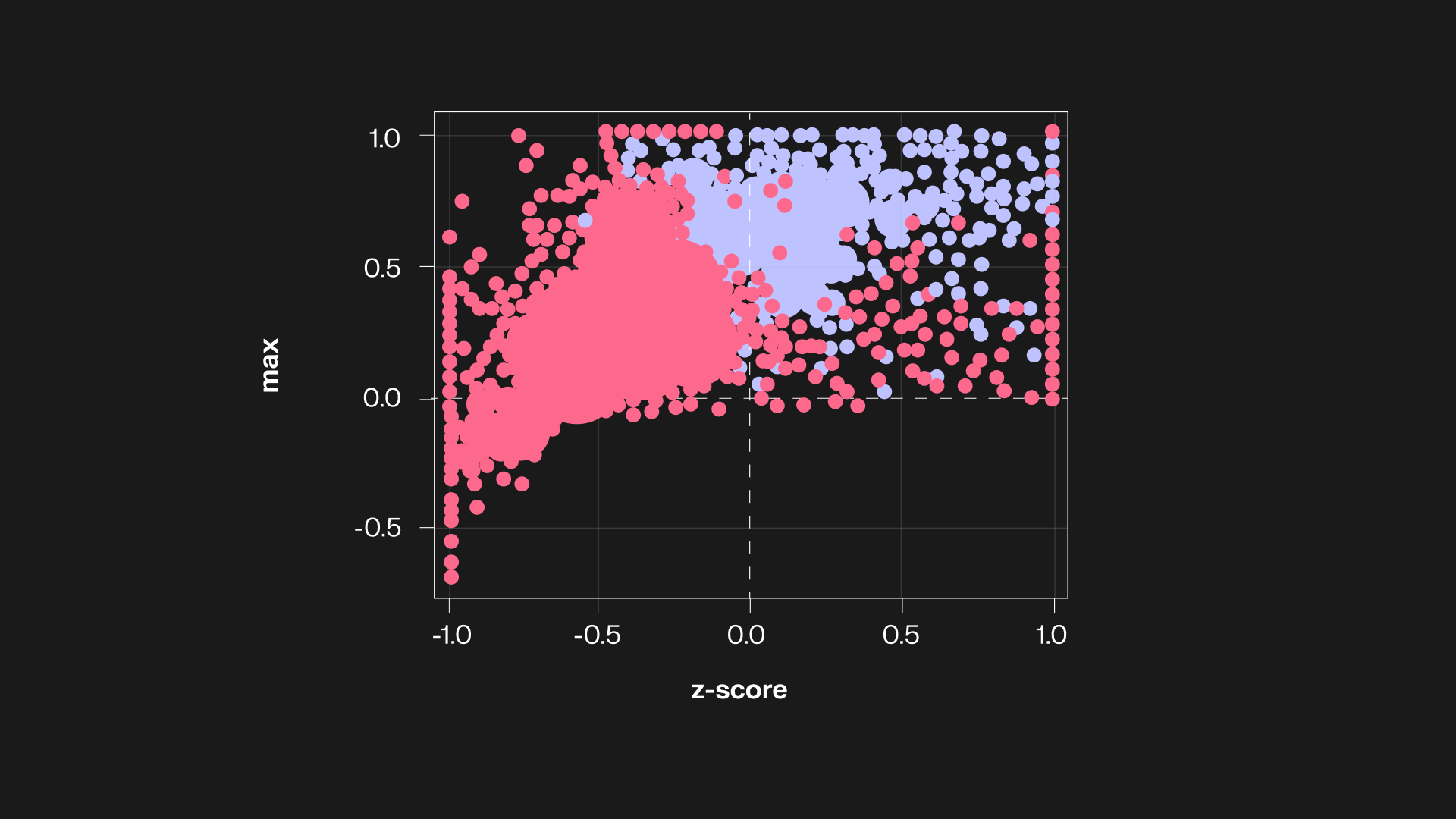
In achieving this fundamental goal, we started by adopting many of the existing methods (from other domains such as backdoor, jailbreaking, and watermarking) in our attacks and were surprised that existing fingerprinting schemes are quite vulnerable. In the process, we also progressively came up with stronger attacks (e.g. output detection and statistical analysis) targeting vulnerabilities unique to fingerprints (e.g. exact memorization) while also maintaining a high utility. We also explored stronger defenses (e.g. approximate verification) to ensure that the vulnerabilities are fundamental shortcomings and not easily patchable.
Overall, relatively simple attacks were sufficient to achieve our goals, which include (i) encouraging the future fingerprinting schemes to adopt our benchmark and be more mindful about robustness in a systematic way, and (ii) provide analyses on the factors affecting such robustness as a path to designing better fingerprints.